A novelty of our living lab implementation is the use of fully-fledged systems that run within a Docker container. Previous living labs were based on pre-computed results only. In our experiments, we validated both approaches and share the results in this blog post.
To determine pre-computed rankings, we handed out the top-k queries (head queries) to the participants for which the results had to be pre-computed. The experimental systems were only able to respond to those queries, which, of course, do not cover the entire user traffic. In contrast dockerized systems are more versatile in the sense that they can deliver results for arbitrary queries.
During the first two weeks of the first round, the amount of logged data at LIVIVO is comparatively low due to systems with pre-computed results for pre-selected head queries. After that, the first dockerized systems was deployed and increasingly more user traffic could be redirected to our infrastructure.
The figure below shows the cumulative sum of logged session data at LIVIVO before (blue) and after (green) the first fully dockerized system went online in the first round.
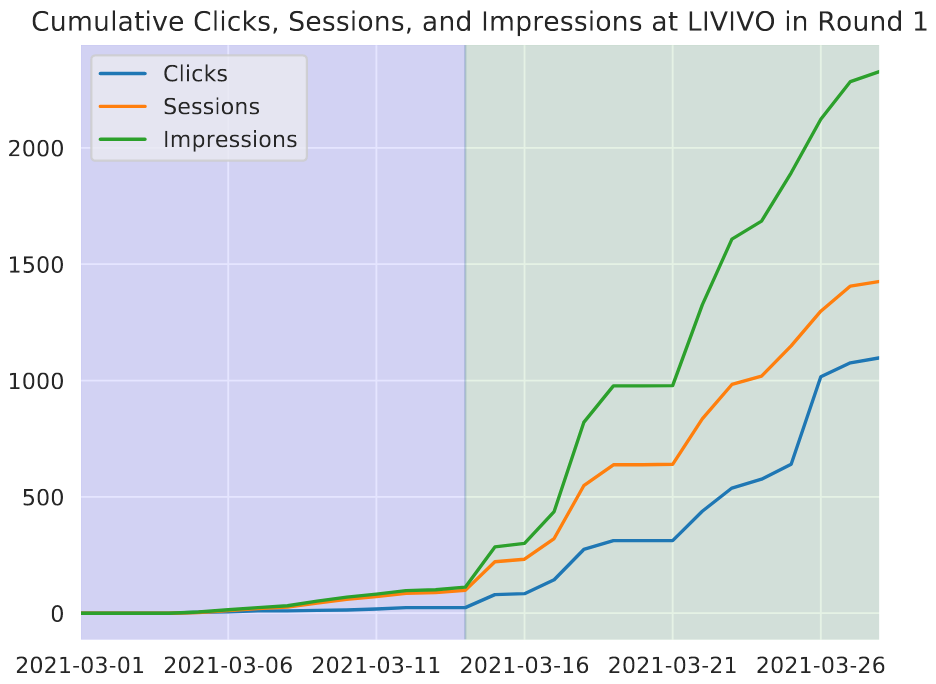
As it can be seen the cumulative sums of logged sessions, impressions, and clicks rapidly increased after the first dockerized system got online in mid-March. We consider the use of Docker containers as a full success and promote its use for future experiments!
More details can also be found in the corresponding lab overview: http://ceur-ws.org/Vol-2936/paper-143.pdf