In this blog post, we share some general information about the [Living Labs for Academic Search (LiLAS)](https://clef-lilas.github.io/) at [CLEF2021](clef2021.clef-initiative.eu/). More specifically, we give an overview about the schedule, participants, and the volume of the logged user interaction data.
The lab was originally split in two separated rounds of 4 weeks each. Due to technical issues for LIVIVO round 1 was four days shorter and round 2 started one week later as planned. To compensate this, we decided to let round 2 last until 24 May 2021, so in total round 2 lasted nearly six instead of four weeks. An overview of the general LiLAS 2021 schedule is given in the table below. Each participating groups received a set of feedback data after each round; the feedback was also made publicly available on the lab website. Before each round a training phase was offered to allow the participants to build or adapt their systems to the new datasets or click feedback data.

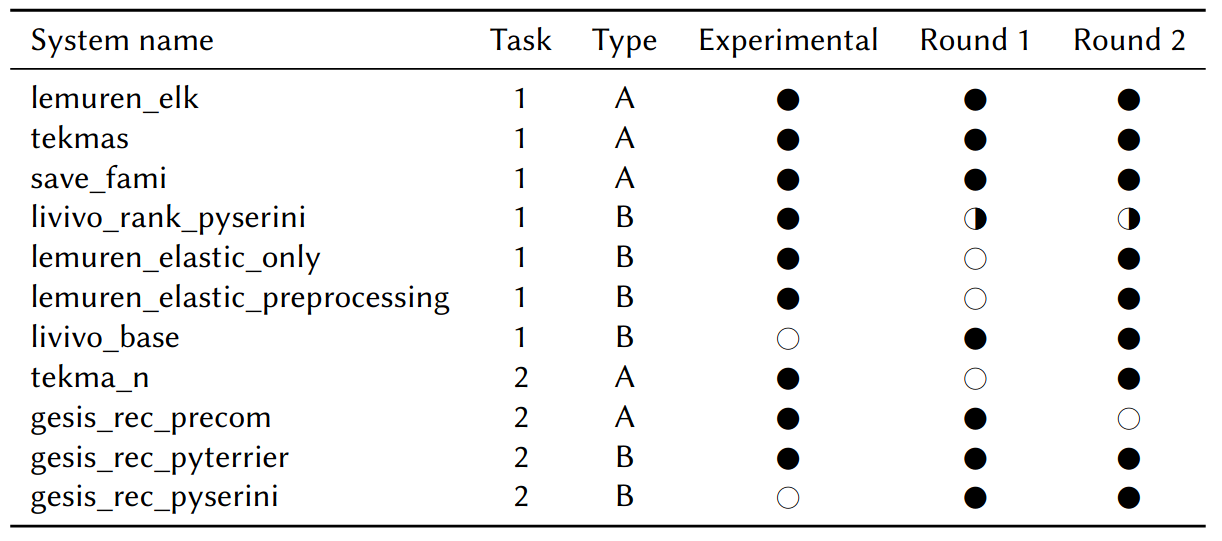
An overview of all systems participating in our experiments is provided in the table below. In the first round, three type A systems (lemuren_elk, tekmas, save_fami) were submitted and deployed at LIVIVO. Since there were no type B submissions in the first round for LIVIVO, we deployed the type B system livivo_rank_pyserini after two weeks in mid-March. In the second round, two type B systems lemuren_elastic_only and lemuren_elastic_preprocessing were contributed. Both systems build up on Elasticsearch, whereas they differ by the pre-processing as outlined before. At GESIS, gesis_rec_pyterrier,submitted as type B system, was online in both rounds. In the first round, the only type A submission was gesis_rec_precom that was substituted in the second round by tekma_n. Both baseline systems at LIVIVO (livivo_base) and GESIS (gesis_rec_pyserini) were integrated as type B systems, emained unmodified, and could deliver results for every request.
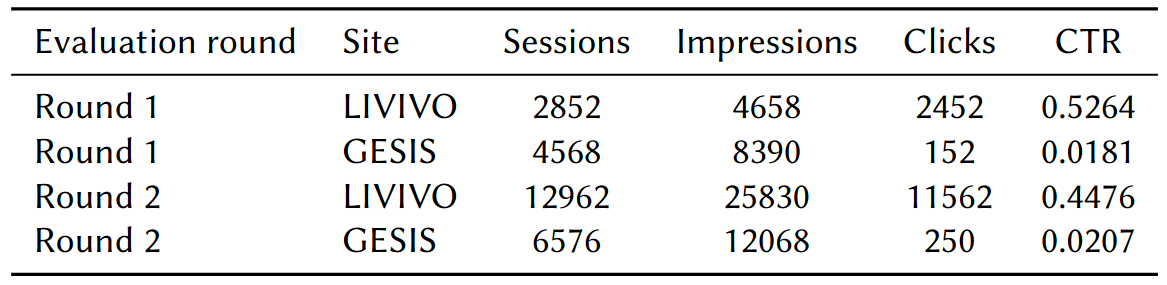
The table below provides an overview of the traffic logged in both rounds. In sum, substantially more sessions, impressions, and clicks were logged in the second round not only due a longer period but also because more systems contributed as Type B submissions. In the first round, systems deployed at LIVIVO were mostly contributed as Type A submissions, meaning their responses were restricted to pre-selected head queries. LIVIVO started the econd round with full systems which delivered results for arbitrary queries and thus more session data was logged. GESIS started both rounds with the majority of systems contributed as type B submissions. In comparison to LIVIVO, more sessions and impressions were logged in the first round, but less recommendations were clicked. Similarly, there are less clicks in the second round in comparison to LIVIVO, which is also reflected by the Click-Through Rate (CTR) that is determined by the ratio between Clicks and Impressions. As mentioned before, GESIS introduced the recommendations of research datasets as a new service, and, presumably, users were not aware of this new feature.
More details can also be found in the corresponding lab overview: http://ceur-ws.org/Vol-2936/paper-143.pdf